
DENVER, CO / ACCESS Newswire / June 6, 2026 / At CVPR 2026 in Denver, Prof. Biwei Huang, Founder of Aether AI and Assistant Professor at UCSD, presented new research on Causal World Models (CWMs) during two workshop sessions. The presentation laid out a structured framework for building AI systems grounded in causality rather than correlation – a distinction that Prof. Huang argues is central to the next generation of physical and embodied AI.

(Figure 1: Prof. Biwei Huang, Founder of Aether AI and Assistant Professor at UCSD, delivers her presentation on Causal World Models at CVPR 2026 in Denver, CO.)
The Correlation Ceiling
The past few years have seen rapid progress across several model families. Large Language Models such as GPT, Claude, and Gemini have demonstrated strong capabilities in natural language and coding. Video generation models like Sora, Wan, and Veo can now produce high-fidelity footage. More recently, Joint Embedding Predictive Architecture (JEPA)-style models have attracted attention for their ability to predict representations in latent space rather than decoding every raw pixel, yielding smoother dynamics and more abstract features.
Yet Prof. Huang made a pointed observation: none of these model families are truly causal. They find correlations – sometimes remarkably well – but they do not model the mechanisms that produce the data.
“Current video and world models lack causal comprehension, leading to inconsistent object physics and imprecise action control,” said Prof. Huang. “Much of the learning still relies on memorizing massive correlation patterns in the data, rather than truly understanding the underlying concepts, mechanisms, and rules that generate the data.”
To drive the point home, Prof. Huang returned to a textbook example: Simpson’s Paradox. In the classic medical case, ignoring a hidden confounder – kidney stone size – leads to entirely contradictory treatment conclusions. The same logic applies in physical environments. Testing has shown that changing a table’s height by just one centimeter can cause a traditional Vision-Language-Action (VLA) robot to fail at a task it previously completed without difficulty. The robot learned a pixel-level correlation, not the physical cause of “contact with a surface.”
Defining a Causal World Model
Prof. Huang proposed that a genuine Causal World Model must satisfy three criteria:
First, learn causal feature representations. The goal is to discover and recover interpretable latent factors – what Prof. Huang calls “concepts” – from raw observations. This stands in contrast to black-box embeddings, where the internal structure of learned features remains opaque. In practice, raw inputs come in many modalities: images, videos, tabular data, time series, gene sequences, sensor signals. Standard approaches fit predictions directly from these observations. But the real data-generating process is typically far more structured – observed variables may be produced by a smaller number of latent factors that themselves carry causal relationships.
Second, understand causal structures. Once the latent factors are identified, the model must map how they influence one another, potentially across hierarchical levels.
Third, capture causal dynamics. The model must learn how the causal system evolves over time under different actions and interventions – not merely how observations correlate across time steps.
Prof. Huang was direct about a widely held assumption in the field: “We often say ‘compression is intelligence,’ but this is not accurate. Simple compression is not enough. We need structured compression – structured compression is intelligence.”
The distinction matters. Compressing raw pixels into a lower-dimensional vector is one thing; recovering a latent space that is compositional, interpretable, and causally organized is another. Only the latter, Prof. Huang argued, unlocks the higher levels of the Causal Ladder: from passive prediction, to active intervention, and ultimately to counterfactual reasoning – the ability to ask “what would have happened if?”
Why Physical AI Needs Causality
A significant portion of the presentation focused on the implications for robotics and physical AI.
In physical environments, Prof. Huang explained, robots cannot rely only on pattern recognition. They need to understand the causal relationships between objects, attributes, actions, and outcomes, and how the state of the environment changes over time. With that understanding, robots can generalize when the environment changes, when the task changes, or even when the robot’s own embodiment changes. They become more robust to distribution shifts and unexpected situations.
“Most importantly,” Prof. Huang noted, “causal world models can support long-horizon reasoning. Instead of only reacting step by step, a robot can reason about how a sequence of actions will influence future states, predict the consequences of interventions, and plan more reliably toward a goal.”
Current video generation models, she argued, fall short of this standard. They rely on pattern recognition in training data, producing impressive outputs but exhibiting imprecise action control, object inconsistency, and violations of physical rules. “Beyond scaling,” Prof. Huang concluded, “we need principles grounded in structure, so that world models truly understand how the world evolves in a causal way.”
Aether AI’s Approach: A Four-Layer Architecture
Prof. Huang also outlined the technical framework being developed at Aether AI, which she described as a Four-Layer Causal Brain Architecture:
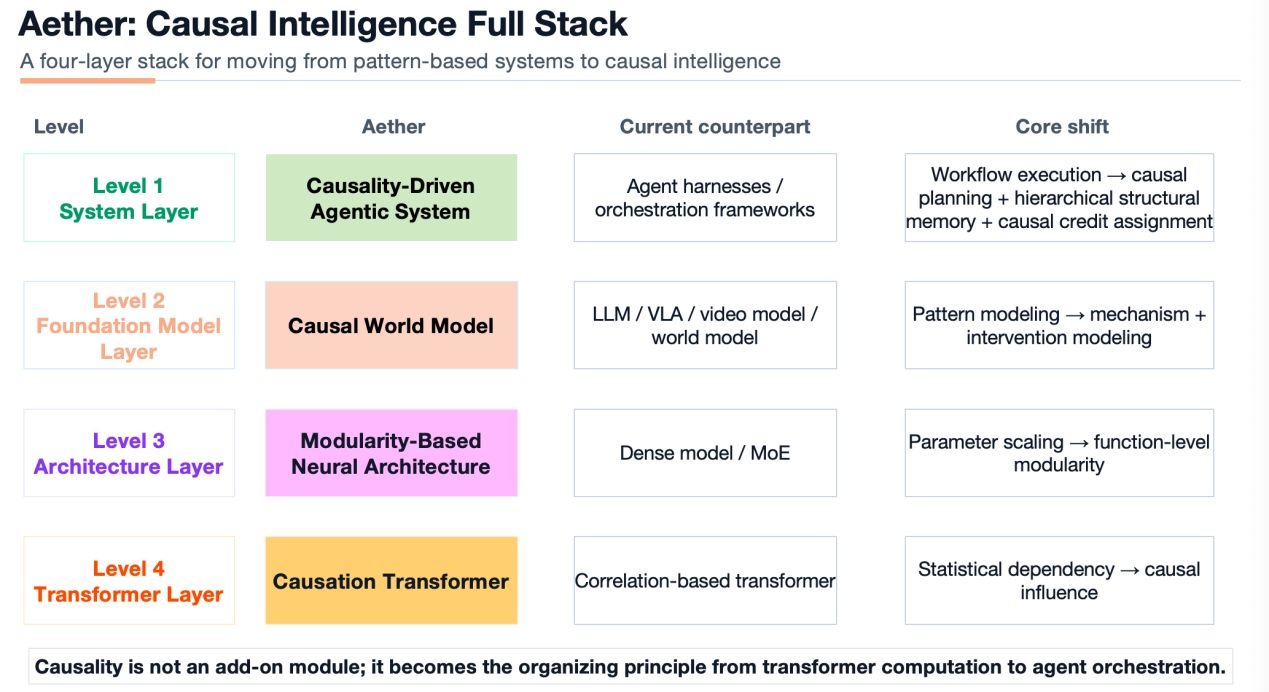
(Figure 2: Aether AI’s Four-Layer Causal Brain Architecture, establishing a structured pathway from system-level agents down to token-level causal infrastructure.)
System Layer – causal-driven agentic systems designed to extract structured information, improving generalization and computational efficiency.
Foundation Model Layer – Causal World Models serving as the core backbone for understanding and prediction.
Neural Architecture Layer – modular network designs inspired by the human brain’s functional specialization, aimed at reducing the redundancy that can arise in current architectures.
Infrastructure / Transformer Layer – modified Transformer architectures that introduce causal dependencies at the token level while preserving scalability.
“Every layer represents a deep technical barrier,” said Prof. Huang. “Globally, very few teams possess the rigorous mathematical and theoretical background to genuinely combine causality with large-scale models.”
Early results have been encouraging. In internal benchmarks against open-source baselines, the team observed significant performance gains on complex robotic manipulation tasks using substantially less training data than conventional approaches require – a result Prof. Huang attributes directly to the causal framework’s ability to learn underlying structure rather than surface patterns.
About Aether AI
Founded by Prof. Biwei Huang, Aether AI is a frontier AI company building causal world models – a new class of AI systems that understand underlying mechanisms, reason under interventions, and operate reliably in complex, real-world environments. Unlike conventional AI approaches that rely on correlation, Aether AI is built on a fundamentally causal foundation, enabling systems to model and reason about the mechanisms that drive real-world outcomes. We believe the next leap in AI will come not from scaling models, but from paradigm-level innovation in how machines learn and reason.
Media Contact:
Company: Aether AI
Contact: Alan Wang
Email: contact@aetherlab-ai.com
Website: https://aetherlabs.ai
SOURCE: Aether AI
View the original press release on ACCESS Newswire